FlexiVoice: Enabling Flexible Style Control in Zero-Shot TTS with Natural Language Instructions
Abstract
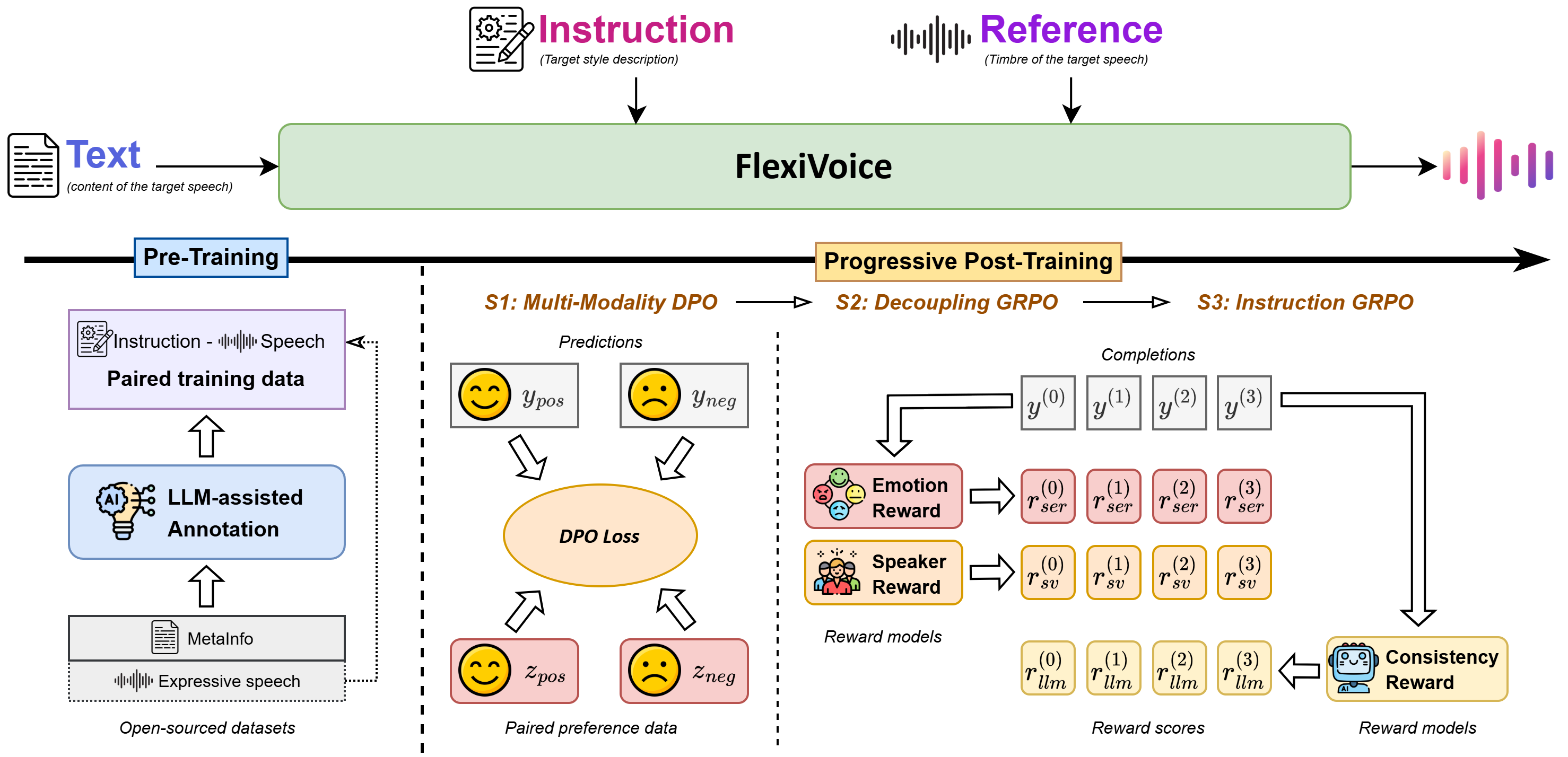
This study proposes FlexiVoice, a text-to-speech (TTS) synthesis system capable of flexible style control with zero-shot voice cloning. The speaking style is controlled by a natural-language instruction and the voice timbre is provided by a speech reference in zero-shot manner. FlexiVoice is built with an LLM core, which takes text as input, and also takes an optional natural language instruction and an optional speech reference to control style and timbre, respectively. FlexiVoice is equipped with a novel Progressive Post-Training (PPT) scheme that progressively unlocks accurate and flexible controllability. In particular, it first employs Direct Preference Optimization (DPO) to enable FlexiVoice to accurately follow both natural language instruction and speech reference simultaneously. It then uses a multi-objective Group Relative Policy Optimization (GRPO) to disentangle style instruction, reference timbre, and textual content. Finally, it adapts instruction GRPO for more advanced instruction following. Experimental results show that FlexiVoice surpasses competing baselines and demonstrates strong capability in decoupling control factors. Human evaluations further confirm its naturalness, controllability, and robustness.
Complex and Open-ended Instruction Following
We sample three English and three Chinese data points from InstructTTSEval, with and without speech reference control.
| Style Instruction | Target Text | Timbre Reference | Ground-truth | FlexiVoice (Ours) |
|---|---|---|---|---|
| Embody the annoyance of dealing with repetitive requests, your voice maintaining bright sharpness and energetic pace with a hint of sarcasm. | Okay, fine. Then I will just go put on your favorite nerdy t-shirt. The one with the guy from Beck to the future on it. |
/ (random voice) |
||
| / | ||||
| Try to sound like a middle-aged radio host with a smooth resonant texture and consistent volume, delivering reports in an objective and formal tone in Standard American English. | Bluth Development Company President George Bluth was arrested tonight for defrauding investors and using the company as his personal piggy bank. More intrigue on the high seas tonight as dozens of local pirates were arrested for protesting the yacht club's discriminatory policies. |
/ (random voice) |
||
| / | ||||
| Deliver the effect of someone revealing a surprising discovery with frantic urgency, keeping listeners focused through a rapid and loud American male voice. | Matt, are you coming? All right, look, forget about that. You don't want to see a dead body anyway. I know that. Look, just come on down here, cover your eyes, and step over the body and show me where the hose is so I can rinse this blood and brains off here. |
/ (random voice) |
||
| / | ||||
| 戏剧性的酒馆老板对顾客夸张地诉苦。 | 哎呀,我的电风扇,你这是败我的家呀。 |
/ (random voice) |
||
| / | ||||
| 以清晰而洪亮的声音宣布节目获奖者,让每一个字都充满感染力。 | 那么今天在现场同样也请来了中科院物理研究所研究员曹泽贤老师, 作为我们现场每一个实验背后的科学顾问和支撑,有请曹老师欢迎你。 |
/ (random voice) |
||
| / | ||||
| 以一种高亢而直率的语调点评朋友近期失败的尝试, 这里面带着些调皮的戏谑。 | 你那哪是打呼噜啊,你那是打炸雷。 |
/ (random voice) |
||
| / |
Emotion-related Instruction TTS
We randomly select 4 samples from our constructed evaluation set, which focuses on emotion-centered instructions. For each sample, an instruction regulates the target emotion, with different conditions:
- 1. Normal text + Neutral speech reference;
- 2. Normal text + Emotional speech reference;
- 3. Normal text + No speech reference (random voice);
- 4. Emotional text + No speech reference (random voice).
| Style Instruction | Target Text | Timbre Reference | Ground-truth | FlexiVoice (Ours) |
|---|---|---|---|---|
| Speak this sentence using happy emotion. | She found herself able to sing any role and any song which struck her fancy. | [Neutral] | ||
| [Sad] | ||||
|
/ (random voice) |
/ | |||
|
I'm angry at how unfairly I was treated in that meeting,
as if my opinion didn't matter at all. [Angry] |
||||
| Express sadness when speaking it. | Don't ask me to carry an oily rag like that. | [Neutral] | ||
| [Angry] | ||||
|
/ (random voice) |
/ | |||
|
I feel happy when I look back at the little memories we've made together. [Happy] |
||||
| 用生气的情感说出这句话。 | 这种社会风气真是让人无语。大家都只顾自己,完全不管别人的感受。 | [Neutral] | ||
| [Happy] | ||||
|
/ (random voice) |
/ | |||
|
回忆起你在我身边的点滴,仿佛在诉说着心中无尽的悲伤。 [Sad] |
||||
| 在语气中表达出吃惊。 | 我原以为这家店只是卖普通的饰品,没想到它竟然有如此独特的手工艺术品,真让人惊艳。 | [Neutral] | ||
| [Happy] | ||||
|
/ (random voice) |
/ | |||
|
人生的很多瞬间都让我觉得痛苦,可我又无力挣扎。 [Sad] |